"Chez Brittany Ferries, on expérimente collectivement l’IA... et ça marche !"
A la tête de la communauté apprenante IA chez Brittany Ferries, Pascale Vinot mise sur l’expérimentation, pas sur les effets d’annonce. Ici on construit l’IA pas à pas, au service des équipes.
 Nicolas François
Nicolas François

Loin des ponts et des moteurs, l’IA chez Brittany Ferries s’ancre d’abord… à terre ! Entre gestion RH, traitement documentaire, sécurité des données et outils métiers, les cas d’usage sont nombreux… à condition d’avoir une approche structurée et collective.
Et c’est justement le cas ici : l’IA n’est pas un projet à part, ni une expérimentation isolée, mais un outil pragmatique, pensé pour accompagner les équipes et améliorer la performance opérationnelle au quotidien.
Pour en parler, j’ai eu le plaisir d’échanger avec Pascale Vinot, que beaucoup connaissent sans doute comme notre “Madame DataTourisme”, un projet national qu’elle a piloté avec beaucoup de passion et de dynamisme pendant plusieurs années :)
Depuis juillet 2024, elle copilote le dispositif IA chez Brittany Ferries, tout en assurant le rôle de DPO adjointe, au sein d’une entreprise de plus de 3 100 salariés dont près de 2 200 navigants.
Comme toujours avec Pascale, on a pu parler sans détour de gouvernance, d’expérimentation, de qualité des données… mais surtout de retours concrets sur la mise en place de l’IA. Passionnant et très instructif :)
Allez, on embarque ! 🛳️
L'IA chez Brittany Ferries : une approche structurée
Nicolas : Quand tu arrives chez Brittany Ferries en juillet 2024, quel est l’état des lieux sur l’IA ?
Pascale Vinot : Quand je suis arrivée, il y avait déjà un vrai intérêt pour l’IA, une volonté de se lancer mais encore des interrogations sur la manière de passer de la théorie à la pratique. Un comité de gouvernance IA avait été constitué quelques mois plus tôt, pour poser le cadre et éviter que chacun parte dans son coin sans contrôle. La direction était à fond sur le sujet avec une volonté de favoriser l’innovation, ce qui est une vraie chance. Il ne restait plus qu’à organiser la mise en musique du projet.

Côté équipes, il y avait de l’envie, de la curiosité, mais aussi pas mal de freins. Beaucoup me disaient “On aimerait bien tester, mais est-ce qu’on a le droit ?”, “Et si on fait une erreur avec les données ?”… Bref, les collègues préféraient souvent ne pas faire plutôt que de risquer de mal faire.
Pour débloquer ça, ma collègue responsable du Data office a rédigé une charte de gouvernance de l’IA. L’idée, c’était de rassurer tout le monde “Oui, vous pouvez tester, mais dans ce cadre-là”. On a aussi organisé des webinaires de sensibilisation, avec des experts externes, pour donner des bases claires sur ce qu’est (et ce que n’est pas) l’IA.
Juste expliquer ne suffisait pas. L’IA, c’est un sujet qui peut rester hyper théorique si on ne le met pas en pratique.
Mais très vite, on s’est rendu compte que juste expliquer ne suffisait pas. L’IA, c’est un sujet qui peut rester hyper théorique si on ne le met pas en pratique. Il fallait donc passer rapidement à l’expérimentation pour vraiment montrer ce que ça pouvait apporter au quotidien.
Comment êtes-vous passés de la sensibilisation aux premières expérimentations ?
On a vite compris qu’il fallait tester pour de vrai. On a monté une communauté apprenante d’une soixantaine de personnes, issues de toute l’entreprise — RH, marketing, IT, relations clients … issues des équipes françaises et anglaises. Objectif : éviter un projet centré uniquement sur les fonctions supports.
On a commencé par des ateliers participatifs, en mode brainstorming. On leur a demandé : “Qu’est-ce qui vous fait perdre du temps au quotidien ?” ou encore “Quelles tâches répétitives vous aimeriez bien automatiser ?”. Résultat : on a eu un mélange d’idées très pertinentes et d’autres… beaucoup plus farfelues ! Mais c’est normal, c’est comme ça qu’on trouve les vrais bons cas d’usage.
Ensuite, on a trié tout ça en fonction de deux critères : est-ce qu’une assistance par l’IA apporterait une vraie valeur métier ? Et est-ce que c’est techniquement faisable sans se lancer dans un projet de 12 mois ? Certains cas pouvaient être testés rapidement, d’autres demandaient plus de réflexion.
On a choisi une approche POC (Proof of Concept) : plutôt que de vouloir tout industrialiser directement, on a préféré tester sur de petits périmètres, voir ce qui fonctionnait, ajuster et améliorer au fur et à mesure. C’est une méthode qui marche bien parce que l’IA évolue à une vitesse folle. Si on attend la solution parfaite, on ne fait jamais rien !
Aujourd’hui, avec un peu de recul, cette approche a déjà porté ses fruits ?
On peut dire que oui ! Ce qui a vraiment fait la différence, c’est qu’on est partis des besoins des équipes et pas d’un outil imposé d’en haut. Ça change tout. Quand les collaborateurs voient tout de suite comment l’IA peut leur simplifier la vie, ça enlève pas mal de freins.
Et puis, le fait de tester rapidement a aidé à montrer que ce n’était pas un gadget. On a eu des petits succès concrets dès le départ, ce qui a rassuré tout le monde. Ça a aussi créé une vraie dynamique : aujourd’hui, les services viennent spontanément nous voir avec des idées, là où avant, on devait aller les chercher.

En fait, ce qui me plaît le plus dans cette approche, c’est qu’on a dépassé l’effet “grande tendance IA” pour entrer dans du concret. Maintenant, l’IA est vue comme un outil utile, pas comme un concept flou ou une menace. On cherche à développer des solutions qui viendront assister les équipes au quotidien, automatiser certaines tâches pour dégager du temps homme sur les tâches à vraie valeur ajoutée.
Une plateforme IA open source pour créer des agents métiers
Une fois ces cas d’usage identifiés, comment avez-vous abordé la partie technique ?
Dès qu’on a commencé à tester des cas d’usage, la question des outils s’est posée. On ne voulait pas se retrouver enfermés dans une solution propriétaire avec des coûts qui explosent à mesure qu’on avance. Donc, on a fait le choix d’une plateforme IA open source, qui est pour le moment administrée par un prestataire externe mais qu’on prévoit de rapatrier chez nous bientôt grâce à notre équipe d’architectes IT. Ça nous permet d’avoir le contrôle total sur nos données (je suis DPO adjointe avant tout !) et de rester flexibles sur les technologies qu’on utilise.
Sur cette plateforme, on peut créer des agents IA sur-mesure, adaptés à nos besoins métiers. Chaque agent tourne avec un LLM (modèle de langage), et l’avantage, c’est qu’on peut changer de modèle selon les besoins. Aujourd’hui, on fait nos tests sur ChatGPT, Mistral AI et Claude.
Par exemple, ChatGPT est super efficace pour la rédaction et l’analyse de texte. Mais pour structurer ou synthétiser un contenu, Claude nous donne souvent de meilleurs résultats. Et pour des questions de souveraineté, on regarde aussi comment intégrer Mistral, notamment sur les sujets plus sensibles ou des tâches qui ne nécessitent pas forcément un modèle ultra-performant.
Qui peut utiliser cette plateforme en interne ?
On voulait éviter que l’IA soit un truc réservé à quelques experts IT dans leur coin. Donc, dès le départ, on a misé sur une approche collaborative et transparente. Aujourd’hui, tous les membres de la communauté IA ont accès à la plateforme, et tous les agents créés sont visibles par tout le monde. Ça évite d’avoir des doublons ou des projets en silo qui ne profiteraient qu’à un seul service.
Chacun peut créer son propre agent IA en ajustant un métaprompt selon ses besoins. Et s’il faut, on peut brancher des bases documentaires internes pour enrichir les réponses ou limiter voire bloquer l’utilisation de données externes. L’objectif, c’est que les équipes puissent tester, affiner et surtout partager leurs avancées, pour qu’on puisse tous en tirer parti.
La plateforme nous donne aussi accès à un journal d’utilisation, qui permet de voir ce qui fonctionne bien, ce qui doit être amélioré, et d’ajuster les réglages au fur et à mesure. Bref, on avance en mode test & learn, et ça marche plutôt bien !
L’IA doit être un outil du quotidien, pas un projet IT qu’on met en place une fois et qu’on laisse tourner en espérant qu’il marche tout seul.
L’objectif final, c’est que chaque équipe puisse construire ses propres solutions IA sans passer par un prestataire ?
Oui, c’est exactement ça. L’idée, c’est que chaque équipe puisse créer et adapter ses propres solutions IA, et qu’on puisse développer une expertise interne qui permet de s’affranchir petit à petit de prestataires externes. L’IA doit être un outil du quotidien, pas un projet IT qu’on met en place une fois et qu’on laisse tourner en espérant qu’il marche tout seul.
Évidemment, on n’a pas foncé tête baissée avec les équipes dans l’inconnu. Le dispositif est piloté par le comité de gouvernance, et pour l’animation je suis largement épaulée par un prestataire externe, qui nous apporte son expertise et accompagne cette montée en compétence avec du coaching et des sessions de formation. Ceux qui sont plus à l’aise avec la technique peuvent rapidement gérer leurs propres paramétrages, tandis que d’autres, qui ont un besoin métier précis, sont guidés pour construire leur agent.
On avance progressivement, de façon transparente, sans forcer les choses. Certains cas d’usage fonctionnent du premier coup, d’autres demandent beaucoup d’itérations et parfois même finissent par être abandonnés. Mais c’est ce qui fait que le dispositif fonctionne : chacun intègre l’IA à son rythme, en fonction de ses besoins réels, sans se voir imposer un outil qui ne lui conviendrait pas.
L’enjeu central : la qualité des données

Dans tous les projets IA, il y a un élément clé qui conditionne la réussite : la qualité des données. Comment avez-vous géré cet enjeu chez Brittany Ferries ?
C’est LE sujet central. Peu importe le modèle IA qu’on utilise, si les données derrière sont mal fichues, ça ne marchera jamais. On a des tonnes de documents : procédures, bases d’info, textes réglementaires… mais ils sont pensés pour des humains, pas pour une IA. Mises en page complexes, sigles internes, phrases à rallonge… Résultat : les réponses peuvent être complètement à côté de la plaque.
Une IA bien nourrie, c’est une IA qui donne des réponses fiables.
On doit revoir la façon dont on structure nos données. Et peut-être que demain on devra systématiquement créer 2 versions des documents : Une version classique, bien présentée pour l’humain et une version “optimisée IA”, plus simple, mieux segmentée, avec des informations bien catégorisées pour que l’IA puisse les exploiter efficacement. C’est un travail qui prend du temps, mais ça change tout. Une IA bien nourrie, c’est une IA qui donne des réponses fiables.
Est-ce que tu peux nous donner un exemple concret ?
Prenons un texte réglementaire, par exemple. Si on le donne tel quel à un agent IA, il risque de donner des réponses approximatives parce qu’il n’arrivera pas à faire la distinction entre les différentes parties du texte. Résultat : il peut mélanger des obligations, des recommandations ou des exceptions, et ça peut poser problème.
Mais si on restructure ce texte en segmentant bien les informations, en identifiant clairement les articles, les obligations, les exemptions, et en ajoutant des métadonnées pour guider l’IA, tout en peaufinant son métaprompt pour lui demander, par exemple, de rester factuel et ne pas interpréter, alors là, on obtient des réponses bien plus précises et fiables.
On a appliqué cette logique à plusieurs types de documents : protocoles internes, manuels RH, FAQ clients… C’est un travail minutieux, mais au final, ça fait une énorme différence sur la qualité des réponses que l’IA peut fournir.
C’est un processus manuel ou vous avez automatisé cette structuration ?
Pour le moment, on fait tout à la main. On a pris un échantillon de documents et on teste différentes façons de les structurer pour voir ce qui fonctionne le mieux. C’est un vrai travail d’artisan ! Mais une fois qu’on aura compris les bons principes, on espère pouvoir automatiser une grosse partie du processus.
Avec notre coach, on teste notamment aux outils de traitement automatique pour préparer et nettoyer nos bases documentaires. L’idée, c’est qu’on ne fasse ce travail qu’une seule fois par document. Une fois structuré correctement, il est exploitable par l’IA en toute autonomie, sans qu’on ait besoin d’y revenir en permanence.
Ça nous évite aussi de perdre du temps à corriger des erreurs ou à re-traiter les mêmes fichiers encore et encore. Bref, on espère un gros gain d’efficacité !
Et aujourd’hui ça fonctionne comme prévu ?
Oui, en tout cas les résultats commencent à arriver petit à petit, et ça a vraiment changé notre manière de voir l’IA. Avant, on pensait que tout reposait sur le modèle IA lui-même : plus il est performant, mieux c’est. Mais en réalité, le vrai levier, c’est la qualité des données qu’on lui donne.
…maintenant, on sait que si l’IA se trompe, c’est souvent parce qu’on ne lui a pas donné les bonnes infos au bon format.
Dès qu’on a commencé à structurer correctement nos documents, on a vu la différence. L’IA donne des réponses plus précises, plus fiables, et surtout, on évite les fameuses hallucinations qui peuvent être un vrai problème quand on traite des sujets sensibles comme la réglementation ou la relation client.
Bref, maintenant, on sait que si l’IA se trompe, c’est souvent parce qu’on ne lui a pas donné les bonnes infos au bon format. Et ça, c’est un changement de mindset important !
Et on travaille en parallèle la précision de nos prompts bien entendu, c’est l’autre clé du succès de nos agents IA !
Déploiement et perspectives

Une fois cette phase d’expérimentation et de structuration des données réalisée, comment envisagez-vous le déploiement à plus grande échelle ?
On a préféré y aller progressivement. L’IA, ça peut autant fasciner que faire peur, donc on voulait éviter l’effet “grand bouleversement” qui mettrait tout le monde sur la défensive.
L’équipe s’est fixé un objectif simple : finaliser plusieurs cas d’usage concrets avant l’été 2025, pour démontrer, preuves à l’appui, que l’IA peut vraiment changer le quotidien. La première promo a démarré en novembre 2024, et un bilan plus complet est prévu pour la fin de l’année.
Ensuite, on va intégrer une nouvelle vague de salariés dans une 2ème promotion au second semestre. L’idée, c’est que ceux qui ont testé en premier deviennent un peu nos “ambassadeurs” et aident les autres à s’approprier l’outil. Ça évite d’avoir à tout recommencer à zéro à chaque nouvelle phase et ça crée une dynamique positive en interne.
Enfin, au-delà de la communauté apprenante, notre comité IA organise des actions plus larges pour embarquer tous les salariés de l’entreprises, comme des webinaires animés par ma collègue experte en IA et data gouvernance, ou encore le déploiement d’un parcours de e-learning fait-maison.
J’imagine que la question du budget et des ressources a aussi pesé dans la balance…
Oui, forcément, à un moment, il faut faire des choix. L’IA, ça peut être un levier puissant, mais si on veut que ça tienne sur la durée, on ne peut pas tout industrialiser en même temps. On doit vraiment prioriser les cas d’usage qui apportent une vraie valeur ajoutée.
Certains projets sont assez simples à généraliser, d’autres demandent plus de temps, plus de ressources, et donc plus d’investissement. Du coup, on regarde attentivement le retour sur investissement (ROI) avant de passer à l’échelle. On suit des indicateurs clairs : combien de temps est économisé, quel est l’impact sur la productivité, est-ce que ça facilite vraiment le travail des équipes ?
On veut éviter de se lancer dans des projets qui coûtent cher mais qui, au final, n’apporteraient pas grand-chose en interne.
Sans compter qu’on doit aussi maîtriser notre temps d’accompagnement en interne, car l’IA n’est pas notre seule mission et nous pilotons ce dispositif « en plus » de nos métiers initiaux.
À plus long terme, quelle est la vision pour l’IA chez Brittany Ferries ?
L’idée, c’est que l’IA devienne un outil du quotidien, aussi naturel qu’un outil de gestion de projet. Aujourd’hui, c’est encore perçu comme un sujet “à part”, un peu expérimental, mais à terme, on veut qu’il soit totalement intégré aux process métiers.
Un des gros enjeux, c’est l’interopérabilité. On ne veut pas que l’IA soit juste un outil supplémentaire à côté des autres. Il faut qu’elle s’intègre directement à nos logiciels métiers, nos bases de données, nos flux d’informations pour qu’elle apporte une vraie valeur ajoutée sans créer de nouvelles contraintes.
Et puis, on garde aussi une marge d’adaptation. L’IA évolue tellement vite qu’il faut qu’on reste agiles, qu’on puisse ajuster nos choix sans être bloqués sur une technologie qui pourrait devenir obsolète dans deux ou trois ans. Bref, on avance, mais on garde la flexibilité nécessaire pour évoluer en même temps que les outils.
Un chantier qui est loin d’être terminé…
Complètement ! Mais on avance avec une méthode qui fonctionne : expérimenter, mesurer, ajuster. C’est ce qui nous permettra d’adopter l’IA de manière utile et durable.
Et pour finir, comment utilises-tu l’IA dans ton quotidien professionnel et dans ta vie personnelle ?
Alors dans ma vie quotidienne au travail, je l’utilise ponctuellement comme aide à la rédaction ou pour synthétiser des contenus, mais surtout avec ma casquette de DPO adjointe, pour aller chercher dans les textes RGPD, les documents de la CNIL et de la Commission européenne… C’est super utile parce qu’il y a plein de documentation dispersée partout, et c’est un gain de temps énorme de pouvoir interroger tout ça avec l’IA.
A titre perso, j’avoue que j’utilise très peu. Quand je rentre chez moi, j’ai déjà bien donné dans la journée, alors je n’ai pas trop envie de relancer ChatGPT ou un autre outil. Du coup, ça reste presque exclusivement pro.
🎙️ Une approche qui inspire
Un grand merci à Pascale pour son témoignage sincère avec une vraie vision terrain !
Ce genre de retour d’expérience nous montre que l’IA peut être adoptée avec méthode, pédagogie et surtout en partant des besoins réels des équipes.
Ce qui m’a marqué
- Une démarche test & learn assumée : on avance pas à pas, on teste, on ajuste
- Une communauté apprenante impliquée dès le départ, loin des silos habituels
- Des cas d’usage construits avec les équipes métiers, à partir de leurs besoins réels
- Le choix d’une plateforme open source, pour rester libres et souverains dans le temps
- Et surtout : un vrai travail sur la structuration des données. Car comme le dit Pascale : “Une IA bien nourrie, c’est une IA qui donne des réponses fiables.”
A retenir
- L’IA n’est pas un projet IT, c’est un outil pour gagner en efficacité au quotidien
- Mieux vaut démarrer petit, mais bien cadré, que viser une industrialisation prématurée
- L’approche collective est un catalyseur de confiance et d’appropriation
- La gouvernance et la pédagogie sont clés pour lever les freins
- Et la qualité des données reste le socle de toute démarche IA sérieuse
 Nicolas François
Nicolas François
🛳️ Quelques mots sur Brittany Ferries
On connaît tous le nom, mais voici quelques repères concrets sur cette compagnie emblématique du transport maritime.
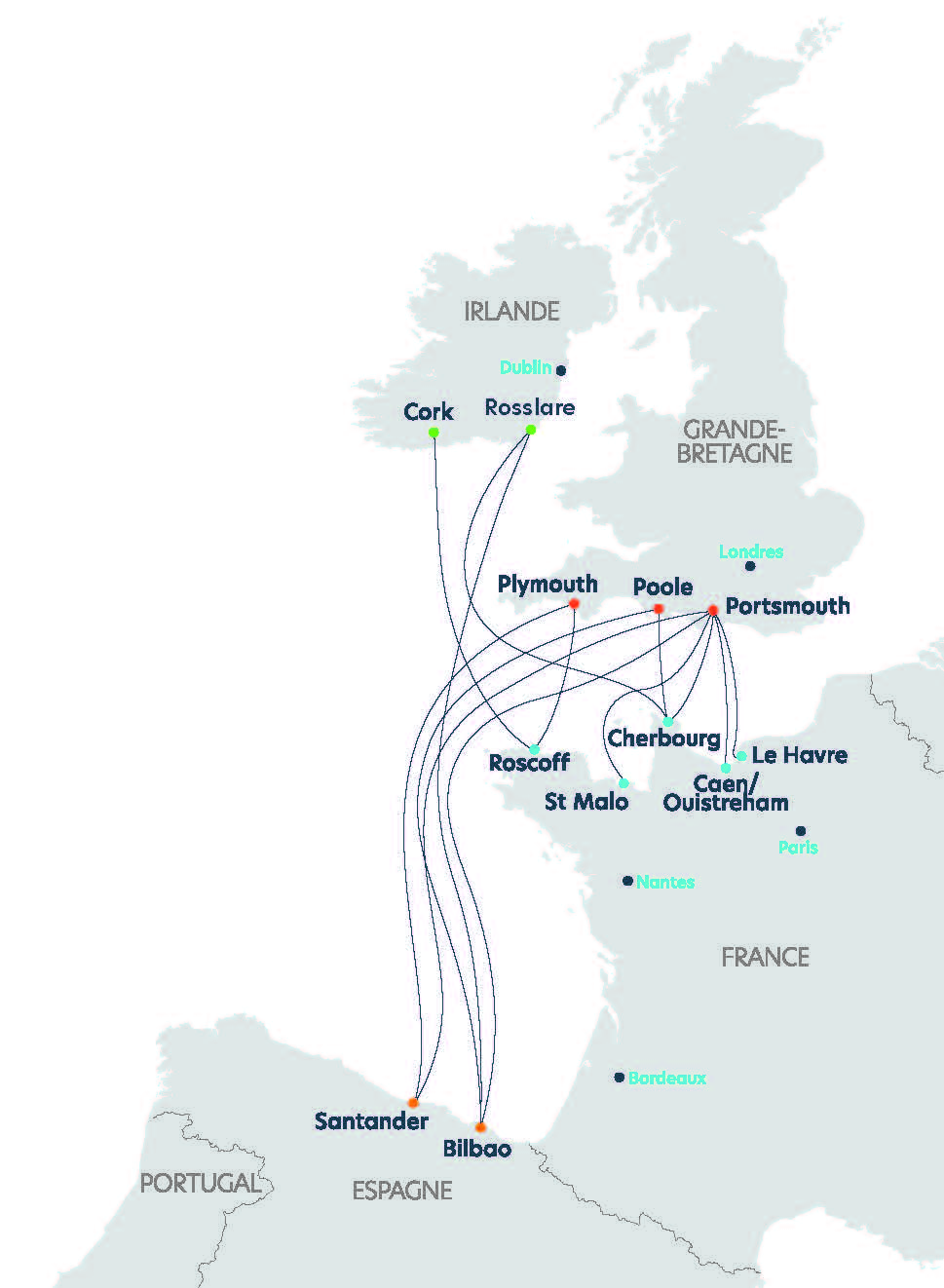
Fondée en 1972 à Roscoff, Brittany Ferries relie aujourd’hui la France, le Royaume-Uni, l’Irlande et l’Espagne. Elle opère principalement sur la Manche et le golfe de Gascogne, avec une flotte de 13 navires.
En 2024, la compagnie a transporté près de 2 millions de passagers, marquant une augmentation de 6,5% par rapport à l’année précédente.
Côté ressources humaines, la compagnie compte plus de 2 700 salariés, dont une majorité de navigants (près de 1 800 personnes). Son chiffre d’affaires 2024 s’élevait à 516 millions d’euros.
Engagée dans la transition écologique, Brittany Ferries renouvelle progressivement sa flotte avec des navires hybrides (GNL/électrique).
👉 Pour les données complètes et à jour, direction le site officiel de la compagnie :
Rejoignez les 2800+ pros du tourisme déjà abonnés
Chaque mois, je décrypte pour vous les enjeux stratégiques de l'IA avec curiosité et bon sens. L'essentiel de la transformation, sans jargon, pour éclairer vos décisions ☕️
S'abonner à la newsletter
Créateur de IA, Tech & Travel Café ☕️. J'aide les acteurs du tourisme à s'approprier l'IA avec curiosité et méthode. Certifié MIT et Directeur Digital, je mets 20 ans de terrain au service d'une IA qui a du sens.